I’ve been working in Luxembourg for more than 13 years now, but I have the feeling that only since my kids arrived have I actually lived in Luxembourg. Mapping the playgrounds, finding new walks, dealing with the schoolmasters and the administration, worrying about their school commute.
Living in a place means getting involved in fixing its problems.
One of the things that looms big on our horizon is the secondary school choice for my older son. The Luxembourgish system seems to force (offer?) plenty of choices: technical vs classical track, international education vs national, private vs public… I’m an engineer, and the core reflex as an engineer is: “measure first” — so I wanted to find ways to compare all these options.
This made me build wiel.lu — a tool to navigate the high-school offerings in Luxembourg. Wiel means “choice” in Luxembourgish, and the project is the fourth stop on a journey that started last summer with obsidize, continued through wee.lu and breakthrough.game — each project more ambitious, each one built faster.
Initially, I wanted to go further: identify the outcomes, results, split them by first languages and origins — things that really count in order to actually make a choice and not a guess. But that data doesn’t exist publicly. Luxembourg even skipped PISA 2022, creating a seven-year gap — the next results won’t land until September 2026. That will be a significant moment: a public, international benchmark after years of silence. I intend to analyse those results in the open — how Luxembourg’s scores compare to 2018, what changed, and what it means for the families navigating the system today.
As it is, wiel.lu is still an interesting tool: it gives you a clear view of what is available in your proximity, how the passing rates compare to the national min/max, how these rates compare between different schools. But it doesn’t say anything about the outcomes you could expect if you choose one school over another. Which basically means there is no choice — the word comes from the French “choix,” from Latin “cogitatus”: to think, to consider. You need data to think, you need data to consider — otherwise it’s only guessing.
So I learned two things from this project:
My “AI-augmented” development flow keeps improving — wiel.lu is more complex and refined than wee.lu or breakthrough.game, and it took less time to build. From idea to a working, deployed application in about three weeks of early mornings.
As it stands, the best way to navigate the school system in Luxembourg is based on word of mouth and insider knowledge — which is something that worries me. The opacity of the education system here is real, and worth questioning. Whether the upcoming PISA results validate the current approach or raise new questions — either way, they deserve to be examined publicly.
Give a spin to wiel.lu — tell me what you think, both about the app and about the general education topic.
A long time ago I got into programming because I wanted to write games. I started with small basic drawing procedures, spinning cubes, things like that.
The thing is, during 30 years of learning, playing and working with computers I never got further than that as my career mostly kept me “on the back-end” – I was stuck.
The new AI assistants allow you now to transform mental images into games, actions, reality – to get unstuck.
I spent a week-end with Claude Code and Cursor – but my kids forgive me because they liked the game.
Introducing my new, early-morning-before-the-kids-wake-up, AI-assisted project:Wee.lu (Wee means “path” in Luxembourgish).
In June 2025, I came across the story of the Zebra30 project. ZUG (Zentrum fir Urban Gerechtegkeet) had crowdsourced information about dangerous crossings in the city — and when the city refused to share its own analysis on crossing compliance, ZUG took them to court. After nearly four years of legal proceedings, they won, and turned that hard-won data access into a map letting residents see how they’re affected — giving them the power to pressure the administration into fixing things. The win mattered on multiple levels: it’s how many people first heard about ZUG (myself included), and it exposed just how far public data access still has to go. It may also have paved the way for broader access, establishing that: “A database that describes ‘a factual situation at a specific moment in time’ is public”(see here).
Around the same time, I “attended” the SciNoj #1 virtual conference and was struck by Heather Moore-Farley’s session on “The Impact of Lane Reductions”. She showed how detailed, accurate public data — specifically, California crash data — analyzed and visualized with Clojure could help a community drive real change and improve safety. After 23 years of building software professionally, and all the talk about how “software is eating the world,” the belief that software could genuinely change things for the better — the very idea that had drawn me into this field — had somehow quietly faded. This talk, and the energy of the conference in general, rekindled that original spark.
What I felt the Zebra30 map was missing was traffic context: a way to measure the real consequences of current conditions, to show how risky each area truly is. A dangerous crossing in a quiet, remote corner of the city is arguably less urgent than one right next to a known accident hotspot. I wanted to add that layer — so I started looking for data on the geographical distribution of accidents across Luxembourg.
Luxembourg has an open data policy (mandated by the Law of 14 September 2018), and several administrations do publish data for open access. Yet I couldn’t find detailed, historically accurate accident location data. There’s simply no public view of where accidents happen across the Grand Duchy.
And yet… this data does exist. Accidents are traffic events, and traffic events are reported in real time by multiple sources in Luxembourg: acl.lu, cita.lu, rtl.lu/mobiliteit/trafic. What’s missing is the memory of these events — specifically, when and where they happened. Someone needs to record that; someone just needs to remember. And memory is everything: LLMs, if nothing else, have made abundantly clear over the past few years just how essential full context is to correctly planning the next step.
But transforming live, real-time events into context — assembling that memory — used to take money, skill, and serious effort. At least, that used to be the case.
“The Cloud” has spent the last decade driving down the cost and technical barrier to running persistent services and storing large amounts of data. Between GitHub Actions (thousands of free minutes) and Google Cloud Storage (tens of GB for a few cents), cost is no longer a barrier. And complexity? You used to need a machine somewhere, Linux skills, the whole deal. Now most of it is a few clicks or a few lines of YAML.
The resources are there. The serverless platforms are ready. The storage is waiting. But you still needed to write the code, test it, and know how to handle every layer of a working solution: back-end, front-end, operations, design, security. Even if you were comfortable with some of it, chances are you dreaded the rest — or simply weren’t good at it.
Enter Claude Code, Codex, Cursor, and friends. They don’t dread any of it — if anything, they’re a little too eager, sometimes reaching for things they shouldn’t touch. They’re not perfect at everything, but if you don’t rush, don’t try to do it all in one go, and force them to stay within guardrails — steering them with your real-world experience of what actually works (and what doesn’t), which is now the main missing ingredient — they’ll help you build all the pieces of a working solution.
The emphasis has shifted slightly: less about raw energy, skill, and curiosity; more about clear vision, experience with the full software development cycle, and a method adapted to these new tools. Not that the first set no longer matters — it’s just increasingly offset by what the tools can do. And there’s a useful side effect of carefully managing context and history for your code assistant: you can always pick up right where you left off, whenever you have a spare hour. That’s ideal when your project only gets early mornings.
Where things stand (early March 2026):
I’ve been collecting accident data since July 2025 — so I’m finally starting to have enough to spot some trends.
I have a first clean version of the visualization map, with the ZUG data layered in for context.
There are still bugs, some that I know:
Translation errors in the interface
Selection issues that vary depending on screen size and zoom level
… and I’m sure plenty I don’t …
What’s next:
Continue updating the data monthly
Experiment with different visualisations (maybe highlighting road segments?)
Improve data consolidation so that nearby markers on the same road don’t cluster awkwardly
Improve positioning at intersections, to more accurately indicate which road is affected
Further evolution (my current ideas – others are welcomed!):
Could Wee.lu use historic Meteolux weather datasets to show how rainy days compare to dry ones? Or to see if certain roads are more accident-prone under specific conditions — snow, for instance?
Maybe add some ways to select specific time frames for the visualisations: periods, night/day selection.
Of course, all of this means more early mornings — so I can’t really say when any of these ideas will actually make it onto the site.
An early conclusion:
It seems that now the present can become actionable memory—community memory, community tools: the dream of Eric S Raymond of the citizen programmer is closer than ever. Will this dream transform our communities and make our lives better, fairer, happier? Or are we going to drown in AI slop? I cast my vote with the first— while admittedly risking to do the second…
What do you think? Take a look at Wee.lu and let me know in the comments.
Thirty years ago, Eric S. Raymond was experimenting with a new way of building software.
The Linux way disrupted the software industry: massively collaborative, powered by the (mostly) unpaid contributions of coders all over the world. It multiplied possibilities and shocked everyone when it proved viable for one of the most complex software projects imaginable at the time: building an enterprise-grade operating system—free, both as in beer and as in freedom.
Raymond’s essay, The Cathedral and the Bazaar, distilled this experience into “the Linux method,” catalysing the open-source movement and a software development approach that is estimated to have created more than $8.8 trillion in value. That code powers much of today’s digital economy and paved the road for the spectacular rise of the software companies now dominating Wall Street.
Once again, we’re standing at the edge of a paradigm shift—this time powered by the transformer architecture and massive investment in large language models. And, as Raymond did three decades ago—though in my own smaller, humbler way—when I felt an unexpected technical itch earlier this year, I decided to experiment with these new tools and this new way of building software.
This is the story of obsidize and what I learned working on it, and it all started with a simple but annoyingitch…
The summer of 2025 was hot—your local weather stats will probably confirm it (thanks, global warming!)—but for me it was especially intense at work, with delivery after delivery, milestone after milestone.
So when I finally started my vacation, I felt the need to re-map where I was. I had to tidy up the things that had accumulated around me while I ran back and forth between work, kids, and more work.
It’s probably no surprise that today, when we “check our environment,” one of the first places we look is our digital space: notes, bookmarks, appointments, personal projects. For me, Obsidian is the system that lets me navigate all this in a way that gives me the illusion—sometimes even the reality—of being in control.
I’ve used Obsidian as my main knowledge management system for two years. Before that, I always used “something” (usually several things at once) to make sense of the endless stream of data from cyberspace: Pocket notes, Reader saves, Kindle highlights. Obsidian, with its vast plugin ecosystem, finally promised to consolidate all that into a usable, productive (?) ecosystem.
Around the same time, I started playing with large language models. At first, it was just testing: could ChatGPT give me a quick summary? But soon it became reflex: start with a dialog, get the lay of the land, then dig deeper into what looked interesting.
Over the last year, I’ve leaned more on Claude from Anthropic—mainly for Claude-Code, but also as a counterpoint to ChatGPT. I like having multiple sources before zooming in on a strategy. The result was an ever-growing pile of notes, conversations, and projects dangling outside my “second brain.” Time to clean that up.
ChatGPT was easy. Community plugins already handled syncing conversations with Obsidian. But I was surprised to find Claude unsupported. (To be clear: from the start I excluded browser extensions and other intrusive options that want wide access to my system.)
Digging further, I discovered that Claude had only recently introduced an export feature, driven by GDPR compliance. Anthropic’s help documentation suggests it was in development as of mid-2024. One small win for EU regulations.
At first, using ChatGPT, Claude, Grok—whatever—felt gimmicky. Like nothing of importance could really accumulate there. But reality disagreed. These chats became central to how I consume and create information. My decisions, my interests, my thinking all sedimented in the chat history of LLMs.
So while I began looking for a quick copy-paste solution to consolidate my notes, the deeper I dug, the more important it became to make this data fully mine, integrated into the system I already use and control.
The good news: the data are available. The bad news: they come as JSON—hardly usable as-is, especially in Obsidian. At first, it looked like I’d have to wait for someone to write a plugin to tidy this corner of my digital self.
But then I thought: wouldn’t it be fair to ask Claude to help me take full ownership of my discussions with Claude?
That itch wouldn’t let me go. And so my vacation turned into a trip into the world of vibe coding: The Scratch.
To build obsidize I started with a simple—or at least straightforward—problem: convert data stored in JSON files to Markdown.
On paper, conversion between standard formats should be one of the strong points of LLMs. In practice, a direct request to Claude or ChatGPT exposed a familiar disadvantage: their wordy answers and tight context limits. The exported files from Claude were simply too big for the standard web interfaces.
And it wasn’t going to be a one-off operation. I’d keep using Claude, creating new conversations, extending old ones. I didn’t want to manually manage exports each time.
So my scope grew. What I actually needed was a tool that could:
Convert JSON data to Markdown files.
Update existing conversations/projects in Markdown with new content, without overwriting edits made directly in Obsidian.
Parsers are supposed to be another strength of LLMs—but the context window ruled out Claude and ChatGPT for this first stage.
That’s when I turned to Google’s Gemini 2.5 Pro. With its huge context window, Gemini had no problem accepting an entire conversation file and proposing a parser in Clojure/Babashka that ran successfully on the first go. Same for the projects file. This is Gemini’s real advantage: not something impossible for other GPTs, especially in agent mode with MCP, but far easier when you just need a quick, working answer.
Now I had two tools/scripts doing essentially the same thing—converting JSON to Markdown—but no update logic.
So I decided to simplify first: solve the conversion problem cleanly before tackling updates.
I spun up a standard Clojure project structure (with deps-new), ported Gemini’s Babashka scripts into namespaces, and asked Claude-Code to turn it into a CLI application.
We discussed the tech stack. For JSON parsing, Claude suggested (and I accepted) Cheshire, a well-established, high-performance library built on Jackson.
Then came the real challenge: implementation choices.
Copilots tend to overdo it. They generate too many options, and every option looks equally viable. The risk is saying “yes” too often and ending up in a swamp of half-working approaches. If you already know the right solution, you can use AI just to speed up coding—but that underuses the tools. If, like me, you often don’t know the right approach, you need to push back and test constantly. Otherwise you get caught in endless loops of “ah, I see the error / the issue is still there.”
With Gemini’s proof-of-concept already working, I just needed to refactor and add a few key features:
Detect input as either an archive (zip/dms) or folder.
Tag and link imported notes for Obsidian.
Most importantly, detect already-imported notes and update them without overwriting edits in Obsidian.
At this point, what started as “tidying up my notes” turned into a small personal quest. I wanted to scratch my own itch, but also to try this new way of building software with new tools. Luckily, my vacation plans were simple: kids, grandparents, clean air, fresh food, plenty of sun.
After about two hours of effective work—spread over three mornings—I had a working Clojure project. Not packaged, but functional. It had documentation, unit tests, and just enough features to be useful.
One incidental advantage of working in VS Code with Gemini and Claude-Code: context switching was painless. Every morning, I could skim the conversation history, remember where we left off, and pick up seamlessly. When the kids woke up, I’d close the lid and shift gears. The next morning, my virtual coworkers were still waiting, ready to continue as if nothing had happened.
With the basics so easy to conjure with digital assistants—and mornings still left in my vacation—I felt confident enough to push toward a real app. The linter and automated tests were already there, but I wanted more:
Building, packaging, getting a real application running on different platforms, on different machines: that’s where your code meets the real world. As a programmer, back in the day, this is where most of my debugging hours went.
At first, using code assistants to build obsidize made it feel like this time would be different.
I discovered Clojure in 2017. The company I worked for was going through an “agile transformation” and, to motivate everyone, handed out copies of The Phoenix Project by Gene Kim. Clojure only gets a few lines in the book—but it’s the language that saves the company, and I took notice. I was already transitioning into coordination/leadership roles, and “getting Clojure” was my way to stay connected to the implementation side. I read the books, built toy apps, but I never shipped a complete, production-ready Clojure application.
In my software developer days, I deployed Java applications to production—almost exclusively back end, single platform, with an Ops team close by.
This time, the Ops team would be Claude, ChatGPT, and Gemini.
The Team
I’ve used Claude-Code since the beta phase. I “got in” at the end of January 2025 and was immediately blown away.
Claude—and most AI tools in VS Code—got a flurry of updates in the first half of August. Every two or three days the Claude-Code extension added something new: agentic mode with custom personas, security-review for uncommitted changes or CI/CD integration, etc. Cool, powerful features that often made me think whatever I did two days earlier could’ve been done easier if I’d just waited.
Occasionally, changes introduced regressions or at least odd behavior. After one update, Claude started committing and pushing changes without my approval. The security-review feature, out of the box, expects the default branch to be set (git remote set-head) and otherwise fails with a cryptic message.
There’s a lot to like about Claude-Code, but for me the killer feature is Custom MCPs—especially how clojure-mcp lets it navigate, modify, and test Clojure applications. So for most of the code development I used Claude-Code—in VS Code or the CLI—jumping out when usage limits kicked in or I wanted a second opinion, which I usually got from a specialized ChatGPT, Clojure Mentor.
For build, packaging, and deployment, I leaned on Gemini and another specialized model, DevOps ChatGPT—also because, at the beginning of August, Claude felt less capable in those areas.
Aiming high
My target was what I ask of any tool: fast, secure, reliable, easy to install, update, and use.
For a Clojure application, fast means GraalVM—melting the Java fat and startup overhead into a native image on par with C/C++. Secure meant up-to-date dependencies and vulnerability scanning. Reliable meant better logging. And easy to install/update—on macOS—means Homebrew.
My AI team supported those choices (they always do!) and gave me starter code and guidance for building the native image and a Homebrew distribution. For Windows it suggested Chocolatey—new to me, but it sounded right.
Getting the CI/deployment pipeline right for macOS (ARM) was relatively easy. Developing on my M2 Air, I could test and fix as needed. I didn’t focus on other platforms at first; I wanted a quick “walking skeleton” with the main gates and stages, then I’d backfill platform support.
The GraalVM build was trickier. I fumbled with build and initialization flags but eventually got it to compile.
In a few steps I had a Homebrew tap ready to install. Hurray!
Reality check
And then reality kicked in. The native image wouldn’t run. The flags I used made the build pass but execution fail. Cue a round of whack-a-mole, primarily with Gemini.
One interesting Gemini-in-VS-Code detail: at the beginning of August, the extension’s interaction model was chat; after an update, it introduced agentic mode. Proof of how fast assistants evolve—and a chance to feel both the pros and cons of each mode.
Before the mid-August update, chats with Gemini 2.5 Pro were fruitful and generally more accurate than other models—just a lot slower. I didn’t measure it, but it felt really slow. Still, solid answers were worth the wait.
After the August 15 release, chat began to… silently fail: after a long reflection, no answer. So I switched to the agent.
Agentic Gemini looked promising: deep VS Code integration (you see diffs as they happen, which Claude-Code later matched), MCP servers, and a similar configuration to Claude—so wiring up clojure-mcp was easy. However, it just didn’t do Clojure or Babashka well. It got stuck in parentheses hell at almost every step. Sessions ended with tragic messages like, “I’m mortified by my repeated failures…” Eventually I felt bad for it. In their (troubling?) drive to make LLMs sound human, Google had captured the awkwardness of incompetence a little too well.
I started to panic. Everything had moved so fast, and I had so many things started—so many “walking skeletons”—with only a few vacation days left. I realized “my AI team” wasn’t going to get me over the finish line alone.
Vacations are too short
The leisurely vacation development phase had to end. I began waking up earlier for uninterrupted work before 8 a.m., skipping countryside trips and extended family visits to squeeze in a few more hours each day.
At that point, shipping was about testing, running, iterating—not generating more lines of code.
The failing native image led me to add a post-packaging end-to-end validation stage, to catch these issues earlier.
After a few tries, the culprit seemed to be the Cheshire JSON library. With no better theory, I switched to the standard clojure.data.json. Unit, integration, and E2E tests made the change a matter of minutes—but it didn’t fully resolve the native-image issues.
All the while I looped through ChatGPT, Claude, Gemini, and old-school Googling: find plausible theories, try fixes, check whether anything improved. This isn’t unique to LLMs—developers have done this for decades to ship in ecosystems they don’t fully control. If it works, it works.
Finally, I got my first successful Homebrew install and full import on macOS ARM. It seemed feasible again to finish before vacation ended.
Then I added Windows and Linux packaging—and everything failed again. I told myself it was a platform access issue, bought a Parallels Desktop license… and then remembered I’m on ARM trying to target x86. Not going to work.
LLMs gave me speed, but the bottleneck was the real world: deployment time, runtime, access to hardware. Without x86 macOS, Linux, or Windows boxes, I cut scope: native image Homebrew package for macOS ARM (my main platform), and an executable image via jlink for other platforms. Even that was painful on Windows, where builds kept failing and GPTs kept getting confused by basic shell automation. Final plan: native image for macOS ARM (done), jlink package (JRE + JAR) for macOS x64 and Linux arm64, and just the JAR for Windows. Time to stop and get back to reality.
Release It!
Stopping is harder than it sounds in the world of code assistants. When tools get more powerful every day—and solve problems that look as hard as the ones left—it always feels like the happy ending is one prompt away. But our complexity isn’t LLM complexity, and vacations are short.
So I stopped. I polished the code, ran multiple reviews, improved the docs. The functionality was good enough for me. I’d done what I set out to do at the beginning of those two weeks. And somewhere along the way, I learned to stop worrying and love to vibe.
I’ve been fascinated by computers—and what they can be taught to do—since my childhood in the ’80s. It always seemed like with the right secret incantation you could open portals to new worlds, new possibilities; you could gain superpowers if only you knew how to conjure the magic.
I wanted this power, and I admired those who had it. It seemed a skill difficult to master, a skill arriving from the future, a skill the grown-ups around me struggled with—which made it all the more desirable.
My first programming experiences came in the early 1990s on clones of the Z80/ZX Spectrum. I used BASIC to draw and animate simple geometric shapes, or later to write (well, copy) games published as text listings in the back of PC Report magazine.
My high school diploma project (Assistant Programming Analyst) was a FoxPro clone of Norton Commander. My engineering diploma project was a C/C++ disk defragmentation application.
FoxPro, disk defragmentation, BASIC (not to mention Pascal, MFC, CORBA, and others): I watched each of these fade into obsolescence during my career. Yet in a way, the essence of programming didn’t change. That first code I wrote 35 years ago—reading input, initializing state, controlling flow, calling library functions—that was programming. That was software. Until 2022.
By then, my understanding of what makes software successful had already shifted. While writing code remained the only way to “teach your computer to do something,” the viability of that “something”—its relevance, cost, and chance of survival—was less about coding and more about capturing real business needs. It was about growing solutions that could evolve with a changing domain, team, or organization (or better yet, growing the right team to build the right solution). I’ve seen too many thousands of lines of clean, elegant code wasted by bad requirements, misaligned business goals, dysfunctional organizations, clueless management. In that world, being “code complete” was just one small step.
Software engineering is about solving real problems with software, in the most cost-effective way possible. And in the projects I worked, the main problems were rarely the code itself. I found myself focusing more on process, specification, and communication.
And then “teaching your computer to do something” changed.
Andrej Karpathy coined the term “vibe coding” to describe letting large language models drive implementation. He called it “fully giving in to the vibes, embracing exponentials, and forgetting that the code even exists.” In this style, the “assistant” is no longer just an assistant: it builds functionality, proposes architectures, suggests next features. The human supplies guidance, feedback, and high-level direction.
On obsidize, I set out to lean on coding assistants as far as they could go. And they can go surprisingly far. By the end, although I spent many hours testing and debugging, I can’t honestly say I’ve read every line of code in the repository.
Of course, I ran black-box end-to-end tests—the “acceptance testing.” I read and reworked the documentation the assistants generated. I zoomed in on specific namespaces when needed, wrote some code, requested features, made architectural decisions. I decided what to implement and when to stop. But I didn’t read every line. I didn’t write (or review) every test.
Does that make me just a responsible babysitter for the code assistants? Was I just vibing, or was I doing proper “AI-assisted engineering”?
In human teams, you’re not expected to read all the code either—not in large projects. You trust your teammates, and that trust is reinforced with conventions, reviews, tests, demos, documentation. Code assistants are new, and the level of implicit trust they deserve is still being defined. But similar checks are emerging in the LLM world: multiple personas to review code from different angles (something Claude-Code already implements), security reviews, chained tasks, and structured implementation phases.
Using code assistants means you’re not only writing code—but you’re not a pure product owner either. Oversight is tighter. You manage direction, but you must also stay close to the code, watch the repo carefully (ready to revert an agent’s mess), validate changes. And unlike with humans, you must be willing to discard huge amounts of work—hundreds of lines, entire modules. Code is cheap now. Agents don’t take ownership of their mistakes. You can’t let sloppy code slip by hoping someone else will fix it later. It’s better to throw it away, redefine the task, and go again. The agent won’t be offended.
That raises another question: if code is cheap, if agents write most of it, does the choice of programming language matter? I think it does. You still need to read it, debug it, play with it when the AI stalls in its stochastic echo chamber. Languages that are well-designed, consistent, and concise may gain an edge. Clojure, for example, is known for brevity (good for context windows and tokens), functional purity, and explicit state handling. And with the Clojure-MCP server, Claude can interact directly with a live REPL—iterating like an experienced developer.
Are coding assistants silver bullets for software development?
It depends on the monster you’re trying to slay.
If you need to churn code faster, or tackle technologies outside your core competence, then yes: they help. I had never finished a production-ready personal project before. I always got stuck on deployment and packaging, lost interest when forced to learn some necessary but boring technology. With AI teammates, I got further than ever.
For companies that see software as a manufacturing task—cranking out features and polishing wheels—assistants will boost productivity. More stuff will be built.
For companies in novel domains, where constraints come from the business environment, assistants can accelerate iteration, get you to working prototypes, let you test hypotheses quickly. Not a silver bullet, but a powerful tool.
In the late ’90s, Eric S. Raymond experimented with a then-new paradigm: the Linux model, open source, massively collaborative, free. That movement powered the cloud and SaaS revolutions. At the time, critics worried free software would kill developer jobs, handing value to corporations. And maybe it did: those $8.8 trillion in open-source software didn’t land in contributors’ pockets, but they did lower corporate costs. At the same time, free software spawned countless small companies that didn’t need to reinvent the wheel.
Did open source create opportunities for software engineers, or take them away? In the early 2000s, you were still expected to implement your own circular buffers, even your own network stack. Today, most software development is an integration exercise of open-source standards. Writing from scratch is a “code smell.” The building blocks changed.
Now the granularity shifts again. Coding assistants—trained on hundreds of millions of open-source lines—are the new layer of abstraction. They integrate the standard industry tools for you, ready to use.
Fed by free and open-source software, we are approaching an uncanny version of Richard Stallman’s vision: software nearly free as in beer, but not free as in freedom. Everyone can create software. Few get paid for it. The agribusiness of code, controlled by a handful of AI companies.
Some see this as the end of the software engineer. I don’t. Those critics have always underestimated what engineering really is. Software engineering has always been about more than code. And maybe, now that code itself is less central, the other parts of the craft—problem framing, communication, iteration, validation—will finally get their due.
This summer I built obisidize: a command line tool that imports Claude conversations and projects as notes into Obisidan.
Obsidize is a small summer vacation project that allowed me to experiment with new ways of building software and has a few nice features:
🔄 Incremental Updates: Detection of new and updated content – only processes what’s changed
🗂️ Structured Output: Creates an organized, “Obsidian friendly” folder structure for your conversations and projects
🏷️ Custom Tagging: Allows adding custom Obsidian tags and links to imported content via the command line
🔄 Sync-Safe: doesn’t use any local/external state files so the incremental updates can be run from different devices
🔍 Dry Run Mode: Allows the preview of changes before applying
If you are looking for a way to backup your conversations from Claude to Obsidian you should take a look.
It can be installed using Homebrew on MacOS and Linux or using its “universal jar” on any platform with a JRE installed (Java 21+). Check the release page.
I wrote more about how I got to do this project here.
The big boys have their Devoxxes and KubeCons, Luxembourg has the Voxxed Days Luxembourg conference which, as we like to think about a lot of events here in Luxembourg, it is for sure smaller but maybe it is also a bit more refined… maybe.
Thursday, on 21st of June 2024, was the first day of Voxxed Days Luxembourg 2024 – the main local software conference organized by the Java User Group of Luxembourg – and what follows are my notes from this day.
1.
Showing the importance of the space industry for the Luxembourg software community(or just as a confirmation that space tech is cool) the conference was kick-started by Pierre Henriquet’s keynote Les robots de l’espace
… It’s true that – to bring the audience with their feet on the ground – software is mentioned twice as the thing that killed a robot in space: first on 13th November 1982 when the end of Viking 1 mission was brought by a software update and then in 1998 when a misalignment between the implementations provided by different NASA suppliers killed the Mars Climate Orbiter.
Still, the talk ends on a positive note for the viability of software in space: last week the Voyager 1 team managed to update the probe’s software to recover the data from all science instruments: an update deployed 24 billion kilometers away on hardware that has been traveling through space for 47 years.
For me the talk confirms again that SRE for a lot of companies is either the old Ops but with some new language or a label to put on everything they do.
My personal view on SRE is that (similar to the security “shift left” that brought us DevSecOps) it is about mindset, tools and techniques and not about a job position… unfortunately (like for DevSecOps), organisations find it easier to adopt the label as a role than to actually understand the mindset shift, new tools, processes and techniques required.
First mention of the day of the Accelerate book, the DORA Metrics and the 4 Software Delivery Performance metrics.
3.
Next, I went to a smaller conference room to see the “How We Gained Observability Into Our CI/CD Pipeline” talk done by Dotan Horovits.
This was the second mention of the DORA metrics:
One of the main ideas of the talk was that the CI/CD pipelines are part of the production environment and should be monitored, traced, and analysed like production systems for issues and performance. It should not be a new idea: if what you produce is software, then your production pipeline is crucial, but the reality is that many companies still treat the CI/CD pipeline as part of something that is mainly Dev team responsibility, with the freedoms and risks that this entails..
Dotan goes into some detail on how they instrumented their pipelines :
collect data on ci/cd pipeline run into the environment variables
create a summary step on the pipeline to collect all the info from the pipeline and store it in elastic search
visualise with kibana/opensearch dashboards:
define your measuring needs – what you want to find/track?
where the failure happened (branch/machine)
what is the duration of each step
are there steps that take more time than the baseline?
monitor the actual infrastructure (computers, CPUs, etc.) used to run your CI/CD pipelines using Telegraf, Prometheus. For more info check the guide
The talk includes even a short but effective introduction in Distributed Tracing and OpenTelemetry that are used for increasing visibility at every layer (OpenTelemetry was another frequent theme in the talks at the conference – and Dotan is well positioned to talk about it as he runs the OpenObservability Talks podcast)
4.
I checked then the Demystifion le functionnement interne de Kubernetes talk. It was actually a demo done by Denis Germain on how you can deploy a Kubernetes cluster one control plane brick at a time.
As somebody who was thrown into using and working with Kubernetes without having time to thoroughly understand its internals I approached this session as a student and took the opportunity to revisit basic K8s concepts.
A note on the general structure of an K8s resource:
A cool new (for me) tool to manipulate digital certificates: CFSSL, and the fact that for ingress controller traefik was preferred..
The Kubernetes Control Plane components deployed during this short talk:
Kube API Server: the entry point into the infrastructure
Kube Controller Manager: the binary that launches control loops on all the apis that exist in k8s to manage the difference between current state and target state.
Kube Scheduler: the planner/workflow manager: the one that actually creates the jobs that are required by the kube controller manager to align the target state with the current state
Kubelet: the agent on the node: it’s the one that actually executes the tasks planned by the kube scheduler. One of the first things it does is to register itself (and the node) on kube api -> containerd is the container engine that actually initiates the container
CNI container network is the element that manages the communication between container
5.
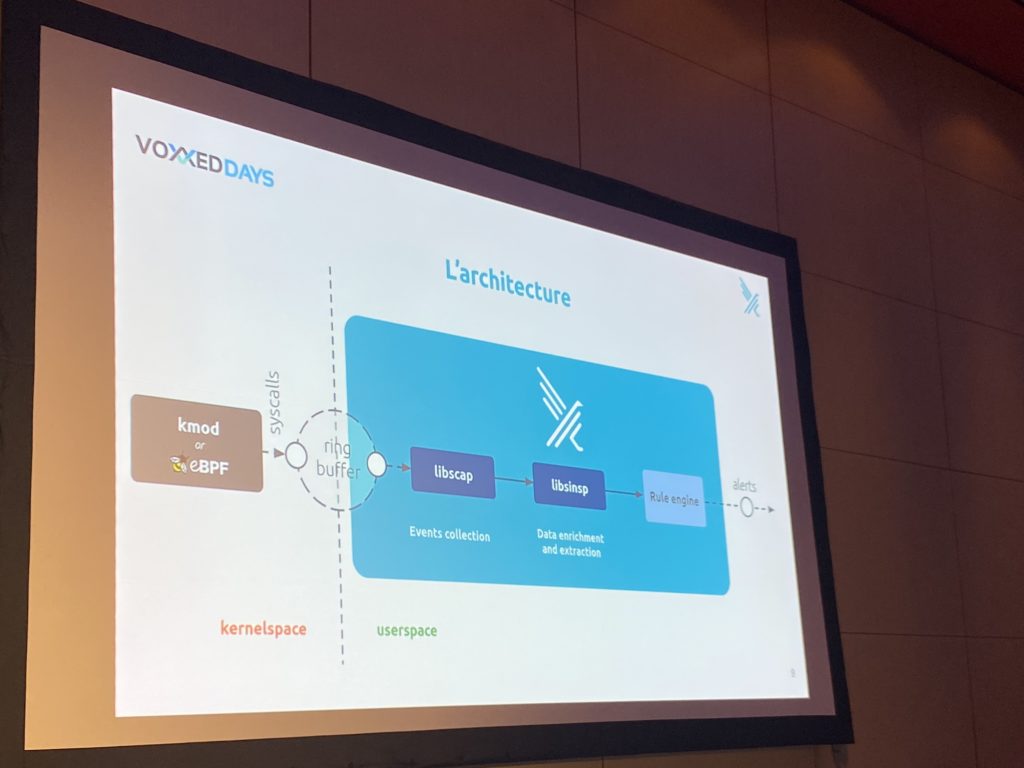
Next: Réagir à temps aux menaces dans vos clusters Kubernetes avec Falco et son écosystème with Rachid Zarouali and Thomas Labarussias.
What I found:
Falco is made by Sysdig – and that Sysdig is founded by Loris Degioanni. My first main professional achievement was moving a network stack (re-implement a subset of ARP, IP, UDP protocols) on winpcap: using winpcap to both “sniff” ethernet packets and also to transmit them with high throughput and precise timing (NDIS drivers… good times!). Winpcap was the base of Ethereal which then become WireShark, and which now continues to live in Falco… I never expected to find echoes of my career beginnings here.
Falco is (now?) eBPF-based, supporting older kernel versions (even pre-kubernetes) which makes sense with its lineage that can be traced to libpcap
falcosidekick – plugin adds additional functionality – created by Thomas Labarussias.
Integrating all the Falco ecosystem you get: detection -> notification -> falcosidekick (actions?)-> reaction (falco-talon)
Falco Talon is a response engine (you could implement an alternative response engine with Argo CD but Falco Talon has the potential of better integration): github.com/falco-talon/falco-talon
Side Note: there is a cool K8s UI tool that was used by Thomas Labarussias during the demo: https://k9scli.io
6.
Next to: Becoming a cloud-native physician: Using metric and traces to diagnose our cloud-native applications (Grace Jansen – IBM)
The general spirit of the talk was that in order to be able to correctly diagnose the behavior of your distributed application(s) you always need: context/correlation + measurements.
The measurements are provided using:
instrumentation – instrument systems and apps to collect relevant data:
metrics – talk emphasised the use of the microprofile.io : an open source community specification for Enteprise Java – “Open cloud-native Java APIs”
traces,
logs
(+ end-user monitoring + profiling)
Storing the measurements is important: send the data to a separate external system that can store and analyse it – Jaeger, Zipkin
Visualize/analyze: provide visualisations and insights into systems as a whole (Grafana?)
Back to Distributed Tracing and OpenTelemetry:
A trace contains multiple spans, a spans contains: span_id, a name, time related data, log messages and metadata to give information about what occurs during a transaction and the context an immutable object contained in the span data to identify the unique request that each span is part of: trace_id, parent_id.
The talk ended with a demo of how all these elements come together in OpenLiberty (OpenLiberty is the new, improved, stripped-down WebSphere).
Side Note: an interesting online demo/IDE tool – Theia IDE.
The third talk mentioning Dora metrics, 2nd that mentions the Accelerate book, the first (and last) that mentions Team Topologies.
The talk adopted a “star wars inspired” story format (which resonates I guess with all the Project Unicorn, Phoenix, etc. readers interested in agile/lean processes). I usually find this style annoying but this time it was well done and Geoffrey’s acting skills are really impressive.
The problem is classical: the organisation (the top) asks some KPIs to measure the software development performance that are artificial when projected onto the real life of the team (even if in this case the top is enlightened enough to be aware of the DORA metrics)
The solution is new: instead of going on the usual “the top/business doesn’t understand so explain them or ignore them” – what Geoffrey offers is: look into your real process, measure the elements that are available and part of your reality and correlate them with the requested KPIs (or, in any case this is my interpretation) – even if they will not fully answer to the request.
From the talks I attended is emerging a general pattern of renewed focus on measurement: for processes (DORA) and for software (OpenTelemetry).
I’d like to think this focus is driven by the de fact that Agile’s principle of Inspect and Adapt becomes second nature in the industry (but is hard to defend this theory in practice knowing how few true Agile organisations are around…)
Of course, for me, Voxxed Days is more than talks and technology – it’s about the people, it’s about meeting familiar faces – people you worked with or just crossed at a meet-up in the city and share the same passion for technology, the software community and the society we are building through our work.
In summary: very good first day – I learned useful things and I’m happy to see that the DORA metrics, the Accelerate book and even really new(2019!) ideas like Team Topologies are finally making inroads into the small corner of the global software industry that Luxembourg represents!